Scaling
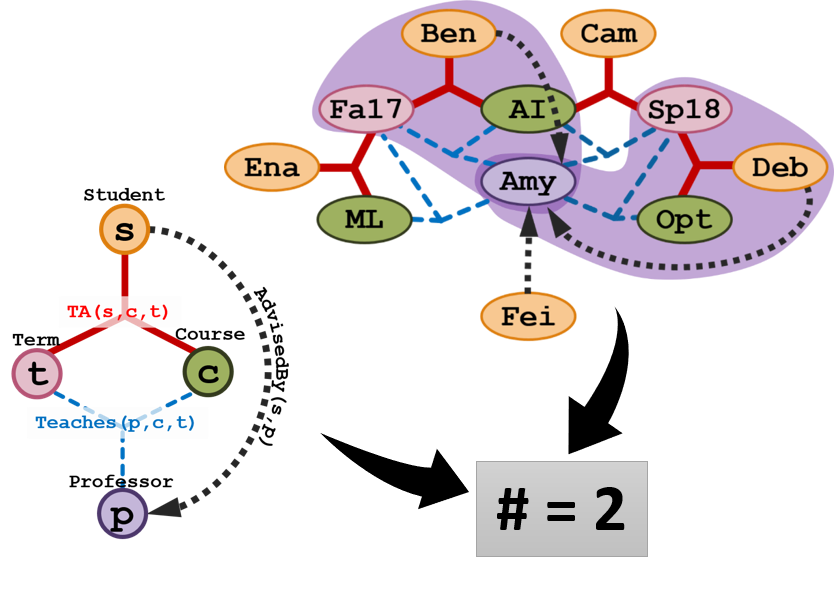
We develop methodologies for fast approximate counting for scalable Statistical Relational AI. In the age of ‘Big Data’, scalability is one of the key challenges both for learning and (lifted) inference in the context of Statistical Relational models. A major bottleneck towards scalable SRL is counting - computing the number of satisfied instances of complex features (# satisfied groundings of First-Order Logic formulas). It is a key operation in SRL (be it for computing the coverage in structure search, for likelihood estimation in parameter learning or for computing cluster size in lifted inference) and is hard, specifically #P-complete, which poses increasingly greater challenges with large scale databases. However, exact computation of counts are inconsequential in context of large/dense data sets. (Example: There will not be any significant change in the popularity of a professor based on whether the papers (s)he has published has 400 or 419 citations) Thus, we develop performance-preserving approximation strategies for such counts, paving the way for scalable and efficient SRL.
Publications
- Das, M., Wu, Y., Khot, T., Kersting, K. & Natarajan, S., “Scaling Lifted Probabilistic Inference and Learning Via Graph Databases”, SIAM International Conference on Data Mining (SDM) 2016.