File Structure
Basic File Structure
Files that BoostSRL operates on are stored in a folder with three things:
background.txt: Modestrain/folder :train_bk.txt: Pointer to the background file.train_facts.txt: Factstrain_pos.txt: Positive examplestrain_neg.txt: Negative examples
test/folder :test_bk.txt: Pointer to the background file.test_facts.txt: Factstest_pos.txt: Positive examplestest_neg.txt: Negative examples
Example:
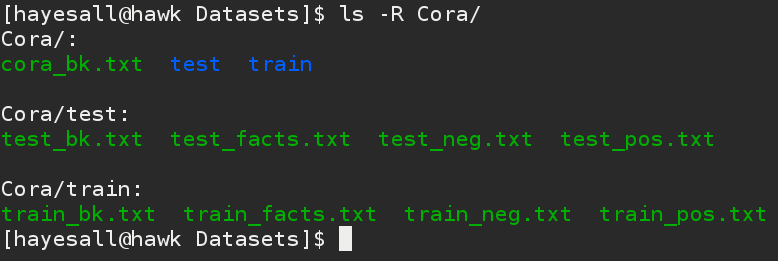
File structure for the Cora dataset, notice that the background is called “cora_bk.txt” in this example.
This is okay if train_bk.txt and test_bk.txt both point correctly with: import: "../cora_bk.txt".
FAQ
- What does it mean to have positive and negative examples during testing? Isn’t the point of testing that I do not know these labels ahead of time?
Think from a classic machine learning perspective. We divide data into training and test sets, learn from training set, hide the labels on the test set, and try to predict what is hidden. Positive and negative examples during testing are hidden, and the goal is to predict which are positive and which are negative based on the learned model and the facts.
If you want to use the model to perform inference on data you do not know the labels for, add your data to either test_pos.txt or test_neg.txt. The regression values in the results_(target).txt can be roughly interpreted as “What is the probability of this example being true/false?”, respectfully.
Advanced File Structure
After training/testing, more files and folders will appear. This advanced guide explains what each of them are, including the contents of the models, dotFiles, bRDNs, and WILLtheories directories.
Not all of these will necessarily appear, for example: the CombinedTrees(target).dot only appears when the -combine flag is set.
1 :Data/
2 :├── background.txt
3 :├── BoostSRL.jar
4 :├── test
5 :│ ├── query_(target).db
6 :│ ├── results_(target).db
7 :│ ├── test_bk.txt
8 :│ ├── test_facts.txt
9 :│ ├── test_infer_dribble.txt
10:│ ├── test_neg.txt
11:│ └── test_pos.txt
12:└── train
13: ├── models
14: │ ├── bRDNs
15: │ │ ├── dotFiles
16: │ │ │ ├── CombinedTrees(target).dot
17: │ │ │ ├── rdn.dot
18: │ │ │ ├── WILLTreeFor_(target)0.dot
19: │ │ │ ├── ...
20: │ │ │ └── WILLTreeFor_(target)9.dot
21: │ │ ├── (target).model
22: │ │ ├── (target)_testsetStats_pos_neg_Lits1Trees10Skew2.txt
23: │ │ ├── old_(target).model
24: │ │ ├── predictions_pos_neg_Lits1Trees10Skew2.csv
25: │ │ └── Trees
26: │ │ ├── CombinedTreesTreeFile(target).tree
27: │ │ ├── (target)Tree0.tree
28: │ │ ├── ...
29: │ │ └── (target)Tree9.tree
30: │ └── WILLtheories
31: │ ├── (target)_learnedWILLregressionTrees.txt
32: │ └── old_(target)_learnedWILLregressionTrees.txt
33: ├── schema.db
34: ├── train_bk.txt
35: ├── train_facts.txt
36: ├── train_gleaner.txt
37: ├── train_learn_dribble.txt
38: ├── train_neg.txt
39: └── train_pos.txt
Data/: Directory that contains the data we train/test on.background.txt: modes file used to guide the search space.BoostSRL.jar: If you’re using a jar file, you’ll usually keep it at the root of the data directory.test/: Directory containing testing data.query_(target).db:results_(target).db: Results of running inference (testing) on the data.test_bk.txt: Pointer to thebackground.txttest_facts.txt: Predicates described in thebackground.txttest_infer_dribble.txt:test_neg.txt: Negative testing examples.test_pos.txt: Positive testing examples.train/: Directory containing training data.models/:bRDNs/:dotFiles/:CombinedTrees(target).dot: Combined Tree of the target, results from using the-combineflag.rdn.dot:WILLTreeFor_(target)0.dot: First of the boosted trees....: For each tree, there will be an associated file namedWILLTreeFor_(target)#.dotWILLTreeFor_(target)9.dot: Last of the boosted trees, equal to one less than the number of trees learned.(target).model:(target)_testsetStats_pos_neg_Lits1Trees10Skew2.txt:old_(target).model:predictions_pos_neg_Lits1Trees10Skew2.csv:Trees/:Combined TreesTreeFile(target).tree(target)Tree0.tree:...: For each tree, there will be an associated file named(target)Tree#.tree(target)Tree9.tree:WILLtheories/:(target)_learnedWILLregressionTrees.txt:old_(target)_learnedWILLregressionTrees.txt:schema.db:train_bk.txt: Pointer to thebackground.txttrain_facts.txt: Predicates described in thebackground.txttrain_gleaner.txt:train_learn_dribble.txt:train_neg.txt: Negative training examples.train_pos.txt: Positive training examples.